최근 SK텔레콤에서 고객의 유심 정보가 유출되었다는 소식이 전해졌어요. 이 사건은 많은 사람들에게 충격을 주었고,
특히 SK텔레콤의 고객이라면 더욱 걱정이 클 것 같아요.
1. SK텔레콤 유심 정보 유출 사건 개요
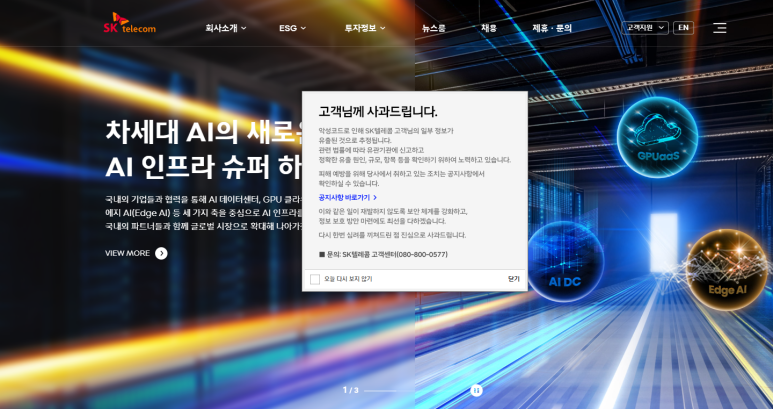
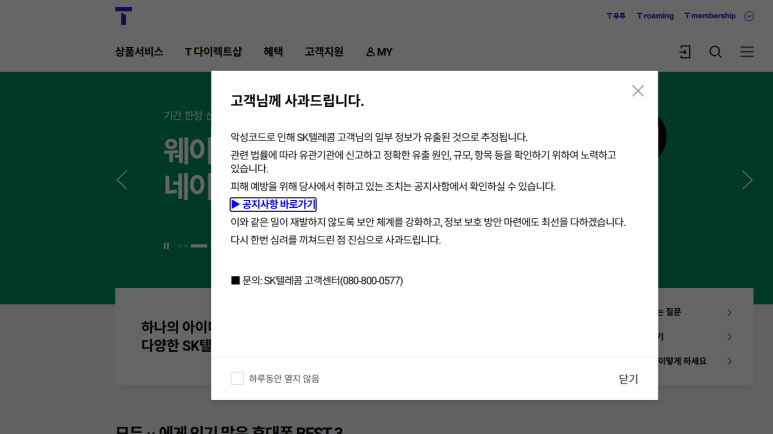
2025년 4월 19일 오후 11시경, SK텔레콤은 내부 시스템에 악성코드가 침투하여 고객의 유심 관련 정보가 유출된 것으로 의심되는 정황을 발견했어요. 이 사건은 단순한 해킹이 아니라, 고객의 개인 정보가 노출될 수 있는 심각한 상황이었죠.
2. 유출된 정보의 종류와 영향
이번 유출 사건에서 노출된 정보는 유심에 담겨 있는 IMSI, IMEI와 같은 가입자 및 단말 고유식별번호, 그리고 ICCID와 같은 심카드 일련번호로 파악되고 있어요. 이러한 정보가 유출되면, 해커가 고객의 통신 서비스를 악용할 수 있는 가능성이 높아지기 때문에 매우 위험한 상황이에요.
3. SK텔레콤의 대응 조치
SK텔레콤은 이 사건을 인지한 즉시 고객들에게 공지를 통해 상황을 알리고, 보안 강화 조치를 취하고 있다고 밝혔어요. 고객들은 공식 발표를 통해 추가적인 피해를 방지하기 위한 조치를 취할 수 있도록 안내받고 있어요.
4. 고객이 알아야 할 사항
고객들은 이번 사건에 대해 주의 깊게 살펴봐야 해요. SK텔레콤은 고객들에게 유심 정보가 유출되었음을 알리고, 공식 발표를 통해 추가적인 정보를 제공하고 있어요. 고객들은 이러한 공지를 주의 깊게 확인하고, 필요시 고객센터에 문의하여 추가적인 조치를 취해야 해요.
5. 향후 보안 강화 방안
SK텔레콤은 이번 사건을 계기로 보안 시스템을 더욱 강화할 계획이라고 해요. 고객의 개인 정보를 보호하기 위해 다양한 보안 기술을 도입하고, 해킹 시도를 사전에 차단할 수 있는 시스템을 구축할 예정이에요. 고객들도 개인 정보 보호를 위해 비밀번호를 주기적으로 변경하고, 의심스러운 링크를 클릭하지 않는 등의 주의가 필요해요.
6. 결론 및 고객의 역할
이번 SK텔레콤 유심 정보 유출 사건은 많은 고객들에게 큰 충격을 주었어요. 하지만 고객들이 주의 깊게 상황을 살펴보고, SK텔레콤의 안내에 따라 행동한다면 추가적인 피해를 예방할 수 있을 거예요. 앞으로도 보안에 대한 경각심을 가지고, 개인 정보를 소중히 여기는 자세가 필요해요.
이 사건에 대한 더 많은 정보는 SK텔레콤 뉴스룸이나 관련 뉴스 사이트를 통해 확인할 수 있어요. 고객 여러분, 항상 안전한 통신 환경을 위해 주의하시길 바랍니다! 😊
FIDO(Fast IDentity Online)는 기존의 아이디/비밀번호 기반 인증의 한계를 극복하고, 보다 안전하고 간편한 온라인 인증을 목표로 만들어진 국제 표준 기술입니다. 패스워드 탈취, 피싱, 리플레이 공격 등에 취약한 기존 방식 대신, 공개키 기반 구조(Public Key Infrastructure, PKI)를 활용하여 사용자가 본인임을 증명합니다.
왜 FIDO 인증이 필요한가?
디지털 환경이 발전하면서 인증의 중요성도 급증했습니다. 하지만 전통적인 비밀번호 방식은 보안과 편의성 모두에서 한계가 있습니다. FIDO 인증은 이러한 문제를 해결하여 다음과 같은 이점을 제공합니다:
패스워드 기반 공격(피싱, 브루트포스, 크리덴셜 스터핑) 방지
생체 인증, PIN 등 다양한 인증 수단 지원
로컬 장치 기반 인증으로 사용자 데이터 보호 강화
다양한 플랫폼 및 기기 간 상호운용성 확보
FIDO 프로토콜 종류
FIDO UAF (Universal Authentication Framework): 비밀번호 없는 인증을 목표로 하며, 생체 인증 또는 PIN을 통해 등록 및 인증을 진행합니다.
FIDO U2F (Universal 2nd Factor): 기존 아이디/비밀번호 로그인에 2차 인증 수단으로 USB 키, NFC 기기 등을 추가합니다.
FIDO2 (WebAuthn + CTAP): WebAuthn API를 이용해 브라우저와 서버 간 인증을 진행하고, CTAP을 통해 로컬 장치와 통신합니다. 완전한 패스워드리스 인증을 지원합니다.
FIDO2 기술 구성요소
WebAuthn (Web Authentication API): 브라우저와 서버 사이에서 인증을 위한 표준 API를 제공합니다.
CTAP (Client To Authenticator Protocol): 사용자 디바이스(예: 지문 리더기, 보안키)와 클라이언트(브라우저 등) 간의 통신을 지원합니다.
FIDO 인증 절차 (등록 및 인증)
등록 과정 (Registration)
서버가 Challenge(난수)를 생성하고, 사용자에게 전달합니다.
사용자는 로컬 디바이스에서 생체정보나 PIN을 입력하여 키 페어(공개키/개인키)를 생성합니다.
패키지가 다른 패키지에서 서비스, 종속성 또는 상수를 가져와야 하는 경우 모호성을 피하기 위해 명시적인 모듈 이름을 사용합니다.
from src.auth import constants as auth_constants
from src.notifications import service as notification_service
from src.posts.constants import ErrorCode as PostsErrorCode
마무리
요약하자면, FastAPI 프로젝트에 적합한 구조를 구축하는 것은 애플리케이션의 확장성, 가독성, 유지 관리를 위해 매우 중요합니다. 코드를 효과적으로 구성하면 코드를 쉽게 관리할 수 있고 변화하는 요구 사항에 적응할 수 있습니다.
우리는 FastAPI 프로젝트 구조의 두 가지 주요 유형, 즉 파일 유형 기반 구조와 모듈 기능 기반 구조에 대해 논의했습니다.
파일 유형 구조는 FastAPI에서 공식적으로 제시한 것으로, 파일을 파일 유형(예: 라우터, 패턴, 모델)별로 구성합니다. 이 구조는 각 서비스가 단일 책임을 갖는 마이크로서비스 아키텍처에서 잘 작동합니다.
반면, 모듈-기능 구조는 파일 유형이 아닌 모듈 기능을 기준으로 파일을 구분합니다. 이러한 접근 방식은 대규모 모놀리식 애플리케이션에 더 적합하며 구성 및 유지 관리가 더 용이합니다.
FastAPI 프로젝트의 구조를 선택할 때 프로젝트 규모, 복잡성, 아키텍처 설계와 같은 요소를 고려하세요. 파일 유형 구조나 모듈 기능 구조를 선택하든, 구성과 명확성을 우선시하는 것은 FastAPI 애플리케이션의 장기적인 성공에 도움이 됩니다.
최근 제출된 서류에 따르면 Consensys, Solana, Uniswap 등이 트럼프 취임식에 수백만 달러를 기부한 암호화폐 회사들 중 하나인 것으로 드러났습니다.
컨센시스, 솔라나, 유니스왑 등 여러 암호화폐 기업들이 트럼프 대통령에게 조용히 기부했습니다.
4월 20일 일요일에 공개된연방거래위원회(FEC)의 최근 보고서에는 암호화폐 업계가 트럼프 대통령 취임식 기금에 기부한 내역이 더 자세히 나와 있습니다.
제출된 자료에 따르면 솔라나 랩스는 주요 기부자 중 하나로 트럼프 취임식에 100만 달러를 기부했지만, 기부 규모는 공개되지 않았습니다. 동시에 탈중앙화 거래소 유니스왑의 CEO인 헤이든 애덤스는 해당 기금에 24만 5천 달러를 기부했습니다. 암호화폐 분석 회사 컨센시스는 별다른 호재 없이 10만 달러를 기부했습니다.
이를 통해 트럼프 대통령은 이 호화로운 행사에 2억 3,900만 달러 이상을 모금할 수 있었으며, 이 행사에는 여러 암호화폐 임원을 포함한 기업 기부자들이 눈에 띄게 참여했습니다.
리플, 코인베이스, 크라켄이 7자리 수의 기부금을 기부했습니다.
이는 다른 암호화폐 기업들이 기부한 수백만 달러에 더해진 금액 으로, 이들은 최초 기금에 가장 큰 기부자였습니다. 특히, 최근 제출된 자료에 따르면 코인베이스, 리플 랩스, 크라켄, 온도 파이낸스, 로빈후드가 모두 이 기금에 7자리 수의 금액을 기부한 것으로 확인되었으며, 이는 앞서 공개된 바 있습니다
리플은 이 행사에 약 490만 달러를 기부하며 가장 큰 기부자 중 하나였습니다. 이보다 더 많은 금액을 기부한 유일한 기업은 미국 가금류 생산업체인 필그림스 프라이드(Pilgrim's Pride Corp)였습니다. 다른 주요 기부자로는 애플과 메타(Meta), 그리고 애플 CEO 팀 쿡이 각각 100만 달러를 기부했습니다. 오픈AI(OpenAI) CEO 샘 알트만(Sam Altman)과 퍼플렉시티 AI(Perplexity AI)를 포함한 AI 기업들도 이 기금에 기부했습니다.
취임식은 미국 정부가 비용을 부담하지만, 취임식 관련 행사는 민간 자금으로 진행됩니다.
이러한 이유로 후보는민간 기부자들로부터 기부금을 모으는 비영리 단체인대통령 취임위원회를 구성합니다.
『Meta FAIR, 인간형 AI 개발 위한 5가지 주요 기술 공개』 출처: Artificial Intelligence News 링크: https://www.artificialintelligence-news.com/news/meta-fair-advances-human-like-ai-five-major-releases/ 요약: Meta의 Fundamental AI Research(FAIR) 팀이 고급 기계 지능(AMI) 개발을 위한 5가지 주요 프로젝트를 발표했습니다. 이번 출시된 기술은 인식 인코더(Perception Encoder), 인식 언어 모델(PLM), Meta Locate 3D, Dynamic Byte Latent Transformer, 그리고 Collaborative Reasoner를 포함합니다. 이 기술들은 AI가 인간처럼 세상을 인식하고 해석하며 소통할 수 있도록 하는 데 중점을 두고 있습니다. 특히 인식 인코더는 이미지와 비디오 작업에서 뛰어난 성능을 보이며, Meta Locate 3D는 로봇이 3D 환경에서 물체를 정확히 찾을 수 있게 합니다. 이러한 기술들은 Meta가 인간과 유사한 지능을 가진 AI 시스템 개발에 계속 투자하고 있음을 보여줍니다.
『화웨이, 엔비디아에 도전하는 AI 하드웨어 혁신 발표』 출처: Artificial Intelligence News 링크: https://www.artificialintelligence-news.com/news/huawei-ai-hardware-breakthrough-challenges-nvidia-dominance/ 요약: 중국 기술 기업 화웨이가 엔비디아의 기술에 도전하는 새로운 컴퓨팅 시스템 'CloudMatrix 384 Supernode'를 공개했습니다. 이 시스템은 300 페타플롭스의 컴퓨팅 파워를 제공하며, 이는 엔비디아의 NVL72 시스템(180 페타플롭스)보다 우수한 성능입니다. 미국의 제재에도 불구하고 화웨이는 국내 공급망에 의존하여 이 기술을 개발했으며, 중국 AI 인프라 스타트업 SiliconFlow와 협력하여 DeepSeek-R1 추론 모델을 지원하고 있습니다. 이는 중국이 AI 컴퓨팅 인프라 구축에 적극적으로 투자하고 있음을 보여주는 사례로, 알리바바 그룹도 최근 3년간 380억 위안(약 524억 달러)을 컴퓨팅 자원과 AI 인프라에 투자한다고 발표했습니다.
『Meta, EU 사용자 데이터로 AI 모델 훈련 계획 발표』
출처: Artificial Intelligence News 링크: https://www.artificialintelligence-news.com/news/meta-will-train-ai-models-using-eu-user-data/ 요약: Meta가 EU(유럽연합) 내 성인 사용자들이 공유한 콘텐츠를 AI 모델 훈련에 활용할 계획을 발표했습니다. 이번 주부터 Facebook, Instagram, WhatsApp, Messenger 등 Meta 플랫폼 사용자들에게 데이터 사용에 대한 알림이 전송될 예정입니다. Meta는 사용자의 개인 메시지나 18세 미만 사용자의 데이터는 훈련에 사용하지 않을 것이라고 밝혔습니다. 이 조치는 유럽 사용자를 위한 AI 도구 개발을 위해 필요하다고 설명하며, 유럽 데이터보호위원회(EDPB)의 의견을 참고했다고 언급했습니다. 그러나 프라이버시 옹호자들은 '옵트아웃' 방식의 동의 시스템과 데이터 사용의 투명성에 대한 우려를 제기하고 있습니다.
『OpenAI, Windsurf 인수 협상 전 Cursor 제작사 접촉』 출처: TechCrunch 링크: https://techcrunch.com/2025/04/17/openai-pursued-cursor-maker-before-entering-into-talks-to-buy-windsurf-for-3b/ 요약: OpenAI가 AI 코딩 회사 Windsurf를 30억 달러에 인수하기 위한 협상에 들어가기 전, Cursor를 만든 Anysphere와 인수 협상을 시도했던 것으로 밝혀졌습니다. CNBC 보도에 따르면, OpenAI는 2024년과 올해 초 Anysphere에 인수 제안을 했지만 협상이 결렬되었습니다. 대신 Anysphere는 약 100억 달러 가치로 자금을 조달하는 방안을 논의 중입니다. Windsurf는 현재 연간 약 4천만 달러의 수익을 올리고 있으며, Cursor는 약 2억 달러의 수익을 올리고 있는 것으로 알려졌습니다. 이는 OpenAI가 코드 생성 시장의 점유율 확보에 얼마나 중요성을 두고 있는지 보여줍니다.
『OpenAI, 저렴한 AI 처리를 위한 'Flex 프로세싱' 출시』 출처: TechCrunch 링크: https://techcrunch.com/2025/04/17/openai-launches-flex-processing-for-cheaper-slower-ai-tasks/ 요약: OpenAI가 더 느린 응답 시간과 "간헐적인 리소스 불가용성"을 감수하는 대신 저렴한 가격을 제공하는 'Flex 프로세싱' API 옵션을 출시했습니다. 최근 출시된 o3 및 o4-mini 추론 모델에 베타로 제공되는 이 서비스는 모델 평가, 데이터 보강, 비동기 워크로드와 같은 우선순위가 낮은 작업을 위한 것입니다. Flex 프로세싱은 API 비용을 정확히 절반으로 줄여줍니다. o3 모델의 경우 입력 토큰당 5/M,출력토큰당5/M, 출력 토큰당 5/M,출력토큰당20/M으로, 표준 가격(10/M및10/M 및 10/M및40/M)보다 저렴합니다. 이는 AI 모델 비용이 계속 상승하는 가운데, Google이 더 저렴하고 효율적인 Gemini 2.5 Flash를 출시하는 등 경쟁이 치열해지는 상황에서 나온 대응책입니다.
『Hence AI, 기업의 리스크 관리를 위한 AI '어드바이저' 출시』 출처: TechCrunch 링크: https://techcrunch.com/2025/04/17/as-the-trade-war-escalates-hence-launches-an-ai-advisor-to-help-companies-manage-risk/ 요약: 런던 기반 스타트업 Hence AI가 조직이 지정학적 및 비즈니스 리스크를 모니터링하는 데 도움을 주는 소프트웨어 제품 'Hence Global'을 출시했습니다. 이 도구는 기업이 리스크를 추적하고 완화 조치를 조언하며, 컨설팅 및 법률 회사가 고객을 위한 의미 있는 분석을 생성하는 데 도움을 줍니다. Palantir의 Foundry와 AI 플랫폼을 기반으로 구축된 이 시스템은 뉴스 헤드라인, 위키피디아, SEC 파일링, 보도 자료 및 제재 목록과 같은 공개 데이터를 분석합니다. 기본 제품은 연간 $1,500로 일반적인 컨설턴트보다 훨씬 저렴하며, 스타트업과 NGO와 같은 조직이 비용 부담 없이 정보에 접근할 수 있게 합니다. 이 제품은 트럼프의 관세 정책으로 인한 지정학적 리스크가 증가하는 상황에서 출시되었습니다.
『DeepSeek의 분산 파일 시스템 소개』 출처: Hacker News 링크: https://maknee.github.io/blog/2025/3FS-Performance-Journal-1/ 요약: DeepSeek이 오픈 소스 릴리스 주간 동안 분산 파일 시스템 '3FS(Fire-Flyer File System)'를 공개했습니다. 3FS는 메타데이터 관리, 클러스터 구성 제어, 실제 파일 데이터 저장, 그리고 모든 노드와 통신하는 클라이언트라는 네 가지 주요 노드 유형으로 구성됩니다. 이 시스템은 CRAQ(Chain Replication with Apportioned Queries) 프로토콜을 사용하여 강력한 일관성과 내결함성을 제공합니다. 분산 파일 시스템은 대규모 데이터(페타바이트까지)를 제공하고 단일 머신의 능력을 초과하는 높은 처리량을 제공하는 장점이 있으며, 병렬 처리 프레임워크, ML 훈련 파이프라인, 대규모 코드/데이터 저장소 등 다양한 응용 분야에서 사용됩니다.
『HDR 적용 이모지 기술』 출처: Hacker News 링크: https://sharpletters.net/2025/04/16/hdr-emoji/ 요약: Slack 이모지에 HDR(High Dynamic Range) 효과를 적용하여 더 밝고 눈에 띄는 반응을 만드는 방법이 소개되었습니다. 이 기술은 Chrome과 Slack에서 잘 작동하지만 Android 기기에서는 지원되지 않습니다. 이모지에 HDR 효과를 적용하기 위해 ImageMagick을 사용한 간단한 스크립트가 제공되었으며, 작업 디렉토리에 2020_profile.icc 파일이 필요합니다. 이 방법을 통해 일반 이모지를 눈에 띄게 밝은 HDR 이모지로 변환할 수 있습니다.
『Erlang/OTP SSH 서버의 인증 없는 원격 코드 실행 취약점 발견』 출처: Hacker News 링크: https://nvd.nist.gov/vuln/detail/CVE-2025-32433 요약: Erlang 프로그래밍 언어용 라이브러리 세트인 Erlang/OTP에서 심각한 보안 취약점이 발견되었습니다. OTP-27.3.3, OTP-26.2.5.11, OTP-25.3.2.20 이전 버전에서 SSH 서버가 인증 없이 원격 코드 실행(RCE)을 허용할 수 있습니다. 공격자는 SSH 프로토콜 메시지 처리의 결함을 악용하여 유효한 자격 증명 없이 영향을 받는 시스템에 무단 접근하고 임의의 명령을 실행할 수 있습니다. 이 문제는 OTP-27.3.3, OTP-26.2.5.11, OTP-25.3.2.20 버전에서 패치되었으며, 임시 해결책으로는 SSH 서버를 비활성화하거나 방화벽 규칙을 통해 접근을 차단하는 방법이 있습니다. GitHub에서 이 취약점에 대해 10.0(심각)의 CVSS 점수를 부여했습니다.
각 샘플을 input_ids, attention_mask, label을 포함하는 사전으로 처리합니다.
tokenizer = AutoTokenizer.from_pretrained("D:\\git\\model-download\\bloom-389m-zh")
defprocess_func(example):
MAX_LENGTH = 256
prompt = "\n".join(["Human: " + example["instruction"], example["input"]]).strip() + "\n\nAssistant: "
instruction_tokenized = tokenizer(prompt, add_special_tokens=False)
response_tokenized = tokenizer(example["output"] + tokenizer.eos_token, add_special_tokens=False)
input_ids = instruction_tokenized["input_ids"] + response_tokenized["input_ids"]
attention_mask = instruction_tokenized["attention_mask"] + response_tokenized["attention_mask"]
labels = [-100] * len(instruction_tokenized["input_ids"]) + response_tokenized["input_ids"]
# Truncate
iflen(input_ids) > MAX_LENGTH:
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]
# Return the processed data
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels
}
# The .map() method applies the processing function to all samples in the entire dataset.
tokenized_ds = ds.map(process_func, remove_columns=ds.column_names) # `remove_columns` removes the original columns, keeping only the new columns returned by process_func.
print("\nChecking the results of the 2nd data process:")
print("Input sequence (input_ids decoded):", tokenizer.decode(tokenized_ds[1]["input_ids"]))
target_labels = list(filter(lambda x: x != -100, tokenized_ds[1]["labels"]))
print("Sequence of labels (labels decoded, after filtering -100):", tokenizer.decode(target_labels))
4단계: 모델 및 PEFT 구성 만들기
이 단계는Prompt-Tuning의 핵심 단계입니다 . "가상 프롬프트 단어"를 초기화하려면 텍스트를 삽입해야 합니다.
텍스트가 분할된 후, 해당 단어 벡터(임베딩)가 가상 프롬프트 단어의 초기값으로 사용됩니다.
마지막 항목은num_virtual_tokens가상 프롬프트 단어 임베딩 벡터의 개수를 나타내며 학습이 필요한 유일한 매개변수입니다.
model = AutoModelForCausalLM.from_pretrained("D:\\git\\model-download\\bloom-389m-zh")
# Configure Prompt Tuning
config = PromptTuningConfig(
task_type=TaskType.CAUSAL_LM, # causal language model
prompt_tuning_init=PromptTuningInit.TEXT, # PromptTuningInit.TEXT means to initialize the “virtual tuning word” with a text embedding, which is better than random initialization.
prompt_tuning_init_text="The following is a dialog between a human and a robot.", # Segment the text and use the corresponding word vector (embedding) as the initial value for the virtual prompt.
num_virtual_tokens=len(tokenizer("The following is a conversation between a human and a robot")["input_ids"]), # The number of virtual tokens, equal to the length of the initialized text split, this `num_virtual_tokens` embedding vector of virtual tokens, is the only parameter to be trained!
tokenizer_name_or_path="D:\\git\\model-download\\bloom-389m-zh"
)
# Apply the Prompt Tuning configuration to the base model via the `get_peft_model` function, which adds the learnable Prompt Encoder inside the model and automatically freezes all other parameters of the base model.
model = get_peft_model(model, config)
# Look at the changes to the model structure, there will be an additional prompt_encoder section
print(“PEFT model structure:”, model)
# Check trainable parameters: print and compare the number of trainable parameters to the total number of parameters.
model.print_trainable_parameters() # 'trainable parameters' is much smaller than 'all parameters'.
5단계: 훈련 매개변수 구성
args = TrainingArguments(
output_dir=". /chatbot_prompt_tuning_explained_zh",
per_device_train_batch_size=1,
gradient_accumulation_steps=8, # gradient_accumulation: equivalent to an effective batch size of 1 * 8 = 8, useful for cases with limited video memory
logging_steps=10, # print logging information (e.g., loss) every 10 steps of training
num_train_epochs=1, # number of training rounds
save_steps=100, # Save model checkpoints for every 100 training steps
# learning_rate=1e-3, # Prompt Tuning can usually use a slightly larger learning rate than full fine-tuning
# gradient_checkpointing=True, # Can save memory, a little slower, can be turned on if memory is low.
)
6단계: 트레이너 만들기
trainer = Trainer(
model=model,
args=args,
tokenizer=tokenizer,
train_dataset=tokenized_ds,
data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),# Data organizer: responsible for composing a batch of samples from the dataset with the necessary padding.
)
7단계: 모델 학습
trainer.train() # Optimize only the parameters of the virtual token, the weights of the base model are frozen.
8단계: 모델 추론 및 효과 표시
프롬프트 튜닝 추론:
1. 추론 중에 훈련된 가상 토큰은 자동으로 입력 시퀀스에 추가됩니다.
2. 가상 토큰은 모델에 특정 스타일이나 콘텐츠의 응답을 생성하도록 지시하는 암시적 힌트를 제공하는 것과 같습니다.
3. 사용자는 이러한 가상 토큰을 볼 필요가 없으며, 모델 내에서만 작동합니다.
표준 프로세스:
1. 원래 기본 모델을 로드합니다.
2. 훈련된 PEFT 어댑터 가중치를 장착합니다.
3.PeftModel.from_pretrained두 가지를 결합하는 데 사용합니다.
# 1. Load the base model
base_model = AutoModelForCausalLM.from_pretrained("D:\\git\\\model-download\\bloom-389m-zh")
# 2. Specify the directory where the PEFT adapter weights are located
peft_model_path = ". /chatbot_prompt_tuning_explained_zh/checkpoint-3357/"
# 3. load the PEFT adapter and apply it to the base model
peft_model = PeftModel.from_pretrained(model=base_model, model_id=peft_model_path)
if torch.cuda.is_available().
peft_model = peft_model.cuda()
print("Model has been moved to the GPU.")
print("The model has been moved to the GPU.") else.
print("CUDA not detected, will run inference on CPU.")
# Prepare the input text
instruction = "What are the tips for the exam?"
input_text = ""
prompt = f "Human: {instruction}\n{input_text}".strip() + "\n\nAssistant: "
print(f"\nInput for reasoning Prompt:\n{prompt}")
# Segment the input text, convert it to tensors, and move it to the device (CPU or GPU) where the model resides
ipt = tokenizer(prompt, return_tensors="pt").to(peft_model.device)
# Use the `.generate()` method to generate the answer, the PEFT model automatically handles the injection of soft prompts
print("Generating responses...")
response_ids = peft_model.generate(**ipt, max_length=128, do_sample=True, top_k=50, top_p=0.95, temperature=0.7)
# Decode the generated token IDs back into text
full_response = tokenizer.decode(response_ids[0], skip_special_tokens=True) # `skip_special_tokens=True` removes special tokens like <|endoftext|>
# Focus on what comes after "Assistant: "
assistant_response = full_response.split("Assistant: ")[-1]
print(f"\n model generated response:\n{assistant_response}")